
|
Sagedus- ja jaotustabel
| | |
kiirabi
0 1
408 73
| |
Sagedustabelit saab koostada käsuga table(..). Tunnusele kiirabi (kas tudeng on vajanud kiirabi abi viimase 2 aasta jooksul: 0-ei; 1-jah) saab näiteks sagedustabeli koostada nii:
table(kiirabi)
|
|
kiirabi
0 1 <NA>
408 73 180
| |
Vaikimisi ei lisata puuduvaid väärtuseid sagedustabelisse. Puuduvate väärtuste esinemiskordade arvu saab loodavasse tabelisse lisada lisaparameetri exclude=NULL abil. Soovi korral saab exclude-parameetri abil ka sagedustabelist eemaldada antud hetkel mittevajalikke väärtuseid.
table(kiirabi, exclude=NULL)
|
|
kiirabi
0 1 Sum
408 73 481
| |
Sagedustabelile (ka mitmemõõtmelistele sagedustabelitele) saab lisada ääresummasid addmargins-käsu abil
addmargins(table(kiirabi))
|
|
|
kiirabi
0 1
0.8482328 0.1517672
| |
Jaotustabel. Osakaalud leitakse sagedustabeli põhjal prop.table-käsu abil:
prop.table(table(kiirabi))
|
|
kiirabi
0 1
84.8 15.2
| |
Jaotustabel. Osakaalud protsentides, ümmardatud täpsuseni 1 koht peale koma:
round(prop.table(table(kiirabi))*100,1)
|
|
kiirabi arv osakaal
0 408 84.8%
1 73 15.2%
| |
Kaunimalt vormistatud sagedus- ja osakaalude tabel
Protsendimärgi lisamiseks protsentuaalsetele osakaaludele kasutame paste-käsku, soovi korral vaata paste-käsu näiteid
siit.
abi=table(kiirabi)
tabel=data.frame(abi,
paste(round(prop.table(abi)*100,1),"%", sep=""))
colnames(tabel)[2:3]=c("arv", "osakaal")
print(tabel, row.names=F)
|
|
naine mees
arv 512 149
osakaal 77% 23%
| |
Sagedused ja osakaalud tabeli ridades
Kuna tunnus sugu on algandmestikus kodeeritud: 1-naine; 2-mees; siis loome esmalt dekodeeritud kujul esitatud tunnuse suguF. Vaata lähemalt factor-käsu näiteid siit.
Seejärel seome sagedustabeli ja protsentuaalsete osakaalude tabeli rbind-käsu abil, kusjuures ümbritseme osakaalud
eest suluga "(" ja tagantpoolt protsendimärgi ja suluga "%)". Tekstide ja arvude kokkusulatamiseks saab kasutada paste käsku, vaata näiteid siit.
suguF=factor(sugu, levels=c(1,2),
labels=c("naine","mees"))
abi=table(suguF)
tabel=rbind(paste(abi," ", sep=""),
paste(round(prop.table(abi)*100), "%", sep=""))
rownames(tabel)=c("arv", "osakaal")
colnames(tabel)=names(abi)
print(format(tabel, justify="right"), quote=F)
|
|
| |
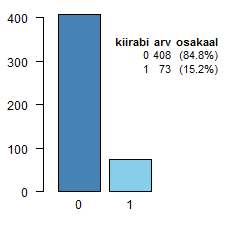
Sagedustabeli lisamine graafikule
Loome esmalt soovitud kuju- ja sisuga sagedustabeli; seejärel teeme meelepärase graafiku ja lõpuks lisame graafikule
meile meelepärasesse kohta varem valmistehtud sagedustabeli.
Graafiku joonistamise ajal peame vajadusel jätma tühja lisaruumi, kuhu hiljem saaksime paigutada sagedustabeli.
Lisaruumi saab graafikule jätta näiteks kasutades xlim= ja ylim= parameetreid, vaata ka siit.
abi=table(kiirabi)
tabel=data.frame(abi,
paste("(", round(prop.table(abi)*100,1),"%)",
sep=""))
colnames(tabel)[2:3]=c("arv", "osakaal")
print(tabel, row.names=F)
# Märka, kuidas xlim= parameetri abil
# tekitatakse graafikule tühja ruumi juurde!
a=barplot(abi, col=c("steelblue","skyblue"),
xlim=c(0,4))
# Loeme sisse abifunktsiooni lisa
source()
# Lisame graafikule loodud sagedustabeli tabel,
# kohast x=1.6 paremale ja ülespoole y=270-st.
lisa(1.6, 270, tabel, adjx=1)
|
|
|
|
|
Leiame tabeli, kus oleks kirjas mitu korda mingit väärtust esines, vastava väärtuse protsentuaalne osakaal, 95%-usaldusintervall protsentuaalsele osakaalule ja ka väärtuste kumulatiivne osakaal (mis antud näites kasutatava tunnuse puhul küll kuigivõrd mõtekas pole. Kumulatiivset osakaalu tasub ehk näidata järjestustunnuste või diskreetsete tunnuste korral, nominaalsete tunnuste puhul - ja perekonnaseis on pigem nominaalne tunnus - pole tegelikult
kumulatiivse osakaalu näitamine soovitatav).
Alljärgnevalt on toodud kolm erinevat, järjest keerukamat programmi sama eesmärgi täitmiseks.
Sisukas tabel
perekonnaseisF arv osakaal UIalumine UIylemine Kum.Osakaal
vallaline 579 87.5945537 84.8369500 90.0107673 87.59455
abielus 17 2.5718608 1.5051818 4.0859405 90.16641
vabaabielus 61 9.2284418 7.1325424 11.6964731 99.39486
lahutatud 4 0.6051437 0.1651201 1.5421061 100.00000
lesk 0 0.0000000 0.0000000 0.5565212 100.00000
Ülaltoodud tabeli tekitas alltoodud programm:
# Tekitame dekodeeritud väärtustega tunnuse
# Eesmärgiks pole mitte ainult parandada tabeli loetavust,
# vaid ka soov saada tabelisse read kõigi vastusevariantide kohta.
# Ilma selle käsuta jääks sagedustabelist välja leskede rida,
# sest valimisse juhuslikult ei sattunud ühtegi leske.
perekonnaseisF=factor(perekonnaseis, levels=1:5,
c("vallaline", "abielus", "vabaabielus",
"lahutatud", "lesk"))
# Leiame sagedus- ja jaotustabeli
a=table(perekonnaseisF)
b=prop.table(a)*100
# Arvutame 95%-usaldusintervallid kõigi
# väärtuste esinemisprotsentidele
UIalumine=rep(NA, length(a))
UIylemine=rep(NA, length(a))
for (i in 1:length(a)){
UI=binom.test(a[i], sum(a))$conf.int*100
UIalumine[i]=UI[1]
UIylemine[i]=UI[2]
}
# Paneme ühte tabelisse kokku sagedustabeli,
# jaotustabeli, leitud 95% usaldusintervalli ja lisame
# nalja pärast veel lõppu kumulatiivsete osakaalude tabeli
tabel=data.frame(
a,
osakaal=as.vector(b),
UIalumine, UIylemine,
Kum.Osakaal=cumsum(b)
)
# Muudame tekkiva tabeli teise rea pealkirja meelepärasemaks
colnames(tabel)[2]="arv"
# Trükime saadud tabeli välja (ilma reanimedeta)
print(tabel, row.names=F)
Ümmardamine
perekonnaseisF arv osakaal UIalumine UIylemine Kum.Osakaal
vallaline 579 87.6 84.8 90.0 87.6
abielus 17 2.6 1.5 4.1 90.2
vabaabielus 61 9.2 7.1 11.7 99.4
lahutatud 4 0.6 0.2 1.5 100.0
lesk 0 0.0 0.0 0.6 100.0
Ülaltoodud tabeli tekitas alltoodud programm:
# Tekitame dekodeeritud väärtustega tunnuse
# Eesmärgiks pole mitte ainult parandada tabeli loetavust,
# vaid ka soov saada tabelisse read kõigi vastusevariantide kohta.
# Ilma selle käsuta jääks sagedustabelist välja leskede rida,
# sest valimisse juhuslikult ei sattunud ühtegi leske.
perekonnaseisF=factor(perekonnaseis, levels=1:5,
c("vallaline", "abielus", "vabaabielus",
"lahutatud", "lesk"))
# Leiame sagedus- ja jaotustabeli
a=table(perekonnaseisF)
b=prop.table(a)*100
# Arvutame 95%-usaldusintervallid kõigi
# väärtuste esinemisprotsentidele
UIalumine=rep(NA, length(a))
UIylemine=rep(NA, length(a))
for (i in 1:length(a)){
UI=binom.test(a[i], sum(a))$conf.int*100
UIalumine[i]=UI[1]
UIylemine[i]=UI[2]
}
# Paneme ühte tabelisse kokku sagedustabeli,
# jaotustabeli, leitud 95% usaldusintervalli ja lisame
# nalja pärast veel lõppu kumulatiivsete osakaalude tabeli
tabel=data.frame(
a,
osakaal=round(as.vector(b), 1),
UIalumine=round(UIalumine,1),UIylemine=round(UIylemine,1),
Kum.Osakaal=round(cumsum(b),1)
)
# Muudame tekkiva tabeli teise rea pealkirja meelepärasemaks
colnames(tabel)[2]="arv"
# Trükime saadud tabeli välja (ilma reanimedeta)
print(tabel, row.names=F)
Hoolikalt vormindatud tabeli näide
perekonnaseisF arv osakaal UI95 kum.osak.
vallaline 579 87,6% (84,8%...90,0%) 87,6%
abielus 17 2,6% (1,5%....4,1%) 90,2%
vabaabielus 61 9,2% (7,1%...11,7%) 99,4%
lahutatud 4 0,6% (0,2%....1,5%) 100,0%
lesk 0
0,0% (0,0%....0,6%) 100,0%
Sunnime R'i vormistama sagedustabeli eesti tavadele vastavalt - nii et komad oleksid
ikkagi komad (2,3) mitte R-i poolt tavaliselt kasutatavad punktid (2.3)!
Programm on pigem mõeldud tarvitamiseks olukorras, kus on regulaarselt (näiteks igapäevaselt, peale uute vaatluste lisandumist) tarvis tekitada kena väljanägemisega tabeleid.
# Tekitame dekodeeritud väärtustega tunnuse
# Eesmärgiks pole mitte ainult parandada tabeli loetavust,
# vaid ka soov saada tabelisse read kõigi vastusevariantide kohta.
# Ilma selle käsuta jääks sagedustabelist välja leskede rida,
# sest valimisse juhuslikult ei sattunud ühtegi leske.
perekonnaseisF=factor(perekonnaseis, levels=1:5,
c("vallaline", "abielus", "vabaabielus",
"lahutatud", "lesk"))
# Leiame sagedus- ja jaotustabeli
a=table(perekonnaseisF)
b=prop.table(a)*100
# Arvutame 95%-usaldusintervallid kõigi
# väärtuste esinemisprotsentidele
UIalumine=rep(NA, length(a))
UIylemine=rep(NA, length(a))
for (i in 1:length(a)){
UI=binom.test(a[i], sum(a))$conf.int*100
UIalumine[i]=UI[1]
UIylemine[i]=UI[2]
}
# Vormistusa algus:
# Vormindame protsendid täpsusega 1 koht peale koma,
# kasutame komakohtade eraldajana eestipärast koma:
UIylemineTXT=formatC(UIylemine, digits=1,
drop0trailing=FALSE, format="f",
decimal.mark=",", width=5)
# Asendame arvu ees tühja ruumi punktidega "."
UIylemineTXT=gsub(" ", ".", UIylemineTXT)
# Vormistame usaldusintervalli väärtused kujule (10,2%...19,4%)
UItxt=paste(
"(",
formatC(UIalumine, digits=1, drop0trailing=FALSE,
format="f", decimal.mark=","),
"%..",
UIylemineTXT,
"%)",
sep="")
# Paneme ühte tabelisse kokku sagedustabeli, eestipäraselt
# vormindatud jaotustabeli, leitud 95% usaldusintervalli ja lisame
# nalja pärast veel lõppu kumulatiivsete osakaalude tabeli
tabel=data.frame(
a,
osakaal=paste(formatC(b,digits=1, format="f",
decimal.mark=",", drop0trailing=FALSE), "%",
sep=""),
UI95=UItxt,
kum.osak.=paste(formatC(cumsum(b),digits=1,
format="f", decimal.mark=",",
drop0trailing=FALSE), "%", sep="")
)
colnames(tabel)[2]="arv"
print(tabel, row.names=F)
|
| |