|
Väärtuste esitusjärjekorra muutmine;
andmestikus mitteesinenud väärtuste lisamine sagedustabelisse või joonisele
Tunnuse väärtuseid näidatakse sagedustabelites ja joonistel selles järjekorras, nagu nad on järjestatud factor-käsu levels=-parameetri taga antud loendis. Samuti tekitatakse sagedustabelisse rida iga levels=-parameetris kirjas oleva väärtuse jaoks, ükskõik kas neid väärtuseid eines antud andmestikus või mitte.
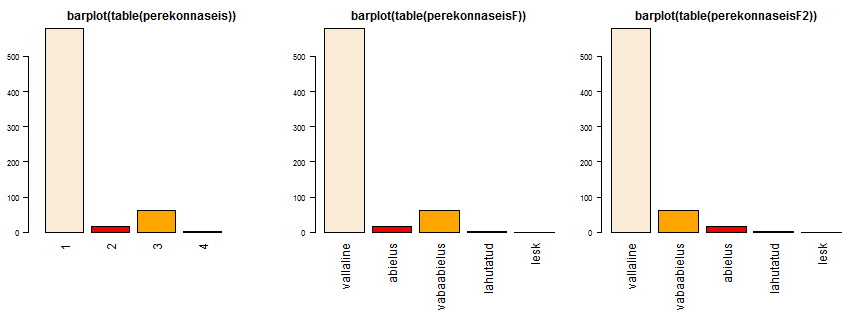
Vaatame järgmist näidet. Tunnus perekonnaseis on kodeeritud järgmiselt:
1 - vallaline
2 - abielus
3 - vabaabielus
4 - lahutatud
5 - lesk
Vaata järgmiseid käske ja nende käskude tulemusena saadud väljundit:
table(perekonnaseis)
Tulemus:
perekonnaseis
1 2 3 4
579 17 61 4
Dekodeerime tunnuse perekonnaseis väärtused. Märka, et sagedustabelisse lisandub üks täiendav veerg (lesk, vastab kodeeritud väärtusele 5)
perekonnaseisF=factor(perekonnaseis, levels=c(1,2,3,4,5),
labels=c("vallaline", "abielus", "vabaabielus", "lahutatud", "lesk"))
table(perekonnaseisF)
Tulemus:
perekonnaseisF
vallaline abielus vabaabielus lahutatud lesk
579 17 61 4 0
Muudame väärtuste järjekorda muutes levels=-parameetriga etteantavate väärtuste järjekorda
(ja muidugi peame siis muutma ka väärtustele vastavate märgendite järjekorda, mis on määratud
labels=-lisaparameetriga). Kui teeme nüüd sagedustabeli vastloodud faktortunnusele perekonnaseisF2, siis on võrreldes eelmise näitega vahetunud väärtuste "vabaabielus" ja "abielus" järjekord.
perekonnaseisF2=factor(perekonnaseis, levels=c(1,3,2,4,5),
labels=c("vallaline", "vabaabielus", "abielus", "lahutatud", "lesk"))
table(perekonnaseisF2)
Tulemus:
perekonnaseisF2
vallaline vabaabielus abielus lahutatud lesk
579 61 17 4 0
Ka olemasoleva faktortunnuse väärtuste järjekorda võime muuta, sellisel juhul pole enam tarvidust
labels= lisaparameetri järele:
proov=factor(perekonnaseisF,
levels=c("lesk", "abielus", "vallaline", "lahutatud", "vabaabielus"))
table(proov)
Tulemus:
proov
lesk abielus vallaline lahutatud vabaabielus
0 17 579 4 61
Sama väärtuste järjekorda kasutatakse ka graafikute joonistamisel. Võrdle näiteks järgmiste käskude tulemust:
barplot(table(perekonnaseis))
barplot(table(perekonnaseisF))
barplot(table(perekonnaseisF2))
|
